

芯东西3月16日消息,近期,台积电的研究人员在ISSCC 2021会议上公布了一种改良的SRAM存储器阵列,该SRAM阵列采用22nm工艺,功率效率为89TOPS/W,运算密度为16.3TOPS/mm
与传统的冯·诺依曼架构相比,该办法能够提升数据传输效率,降低设备功耗,满足未来AI边缘应用的部分需求。
台积电通过扩展常规SRAM阵列,提供了一种高面积效率的存内计算方法,支持可编程位宽、有符号或无符号以及4种不同位宽权重的输入激活。
在最近的2021年国际固态电路会议(ISSCC 2021)上,多个技术会议针对存储器阵列技术展开,以支持机器学习算法的计算需求。
当前,机器学习需要将数据和权重从内存移动到处理单元,然后将中间结果存储回内存。这一方法效率较低,其无谓的信息传输不仅增加了计算延迟,也增加了相应的功耗。
其“无增值”的数据移动是耗散能量的很大一部分,甚至大于“增值”计算的能量消耗,数据和计算单元权重实际只消耗了一小部分能量。
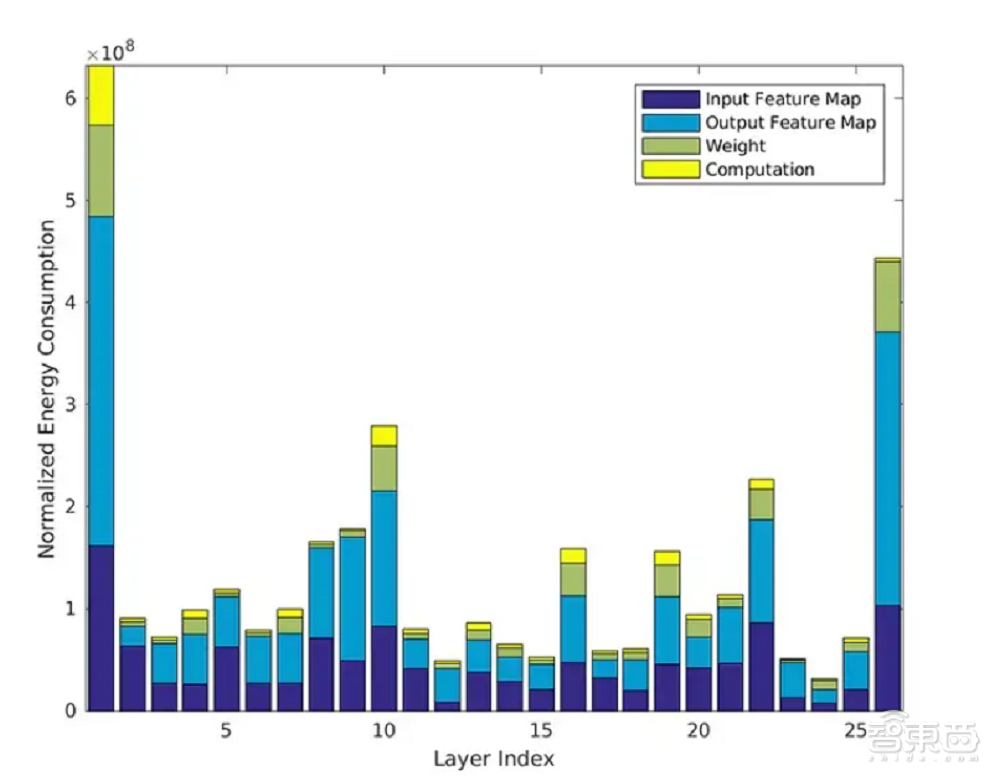
对于在边缘应用机器学习的系统来说,提高存内计算效率、降低能量损耗十分重要。如果想要提高机器学习存内计算效率,重点在于优化每个神经网络节点关联的向量乘法累加(MAC)操作。
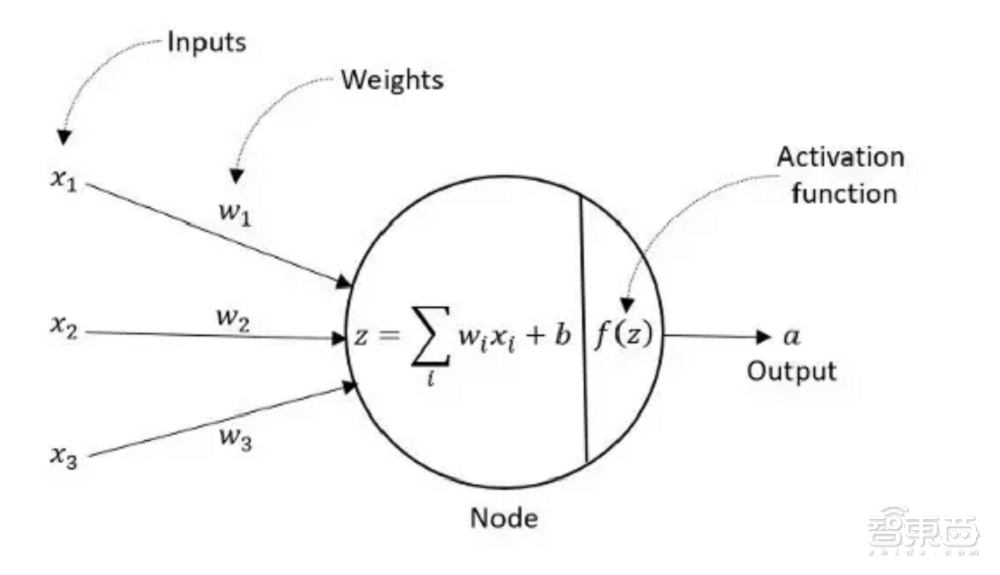
对于一般网络来说,数据和权重通常是多位数。经过训练的边缘AI网络中的权重向量对于可以使用有符号、无符号或二进制补码整数位表示形式,存内计算的MAC输出则是通过添加部分乘法乘积实现的。
每个节点中(数据*权重)的位宽是明确定义的。例如,2n-bit向量覆盖2n-bit无符号整数乘积。如果想要将所有(数据*权重)乘积累加到高度连接的网络中,需要更多bit才能准确表示MAC结果。
当前存内计算研究的一个重点方法是:使用电阻式RAM(ReRAM)实现位线电流检测。活动存储器行字线的数据输入和存储在ReRAM中权重的乘积会产生可区分的位线电流,该电流用于为参考电容充电。
之后模数转换器(ADC)将该电容电压转换为等效的二进制值,进行后续的MAC移位累加。
1、由于电压范围、噪声和PVT的变化,模拟位线电流检测和ADC的精度受到限制;
因此在推理神经网络较小、数据矢量表示受到限制(8位或更少)时,使用ReRAM阵列能提高面积效率。
但是当神经网络较大、数据精度要求很高,存储阵列需要更大的网络和重构工作负载的情况下,更新权重经常会阻碍ReRAM对位电流进行检测。
在ISSCC上,台积电的研究人员提出了一种替代ReRAM的方法,他们使用改良的SRAM阵列进行(数据*权重)计算,这种方法不需要采用更新的存储技术,因此能支持更大的神经网络。
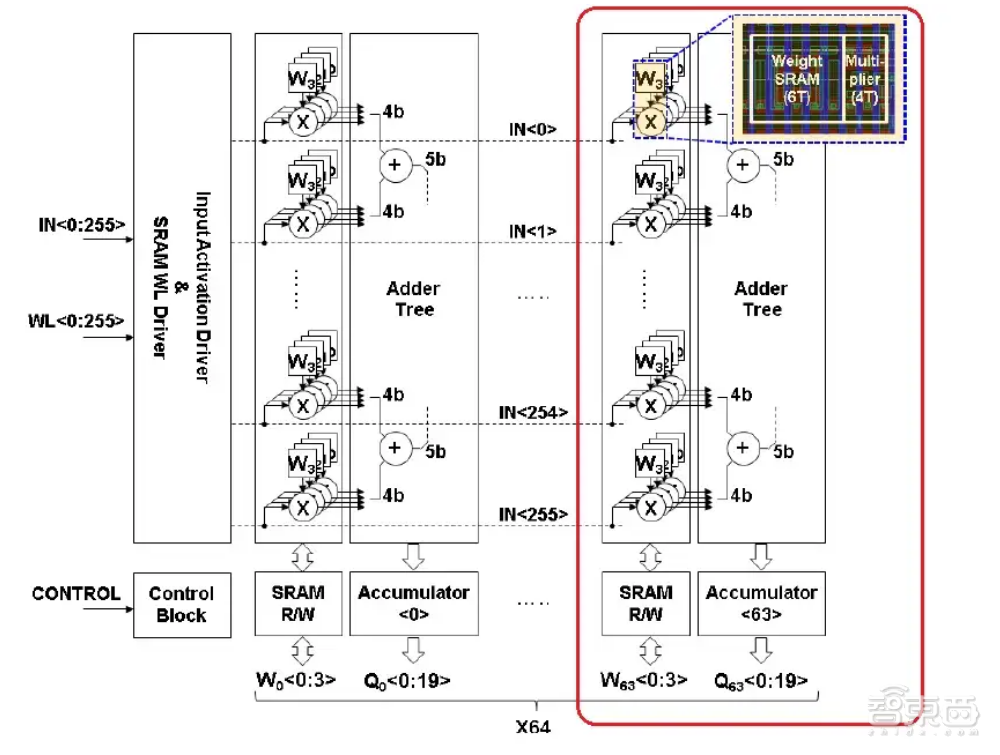
如果层数较大,SRAM阵列可以加载数据输入与权重进行节点计算,可以保存输出值并对后续层进行检索。与ReRAM相比,SRAM阵列减少了数据和权重传递的能耗,解决了ReRAM的耐用性问题。
每个slice具有256个数据输入,它们连接到“X”逻辑电路,数据输入向量的连续字节在时钟周期中被提供给“X”门。一个slice中存储了256个4-bit权重,每个数据输入代表一个权重,每个权重连接到“X”逻辑的另一个输入。
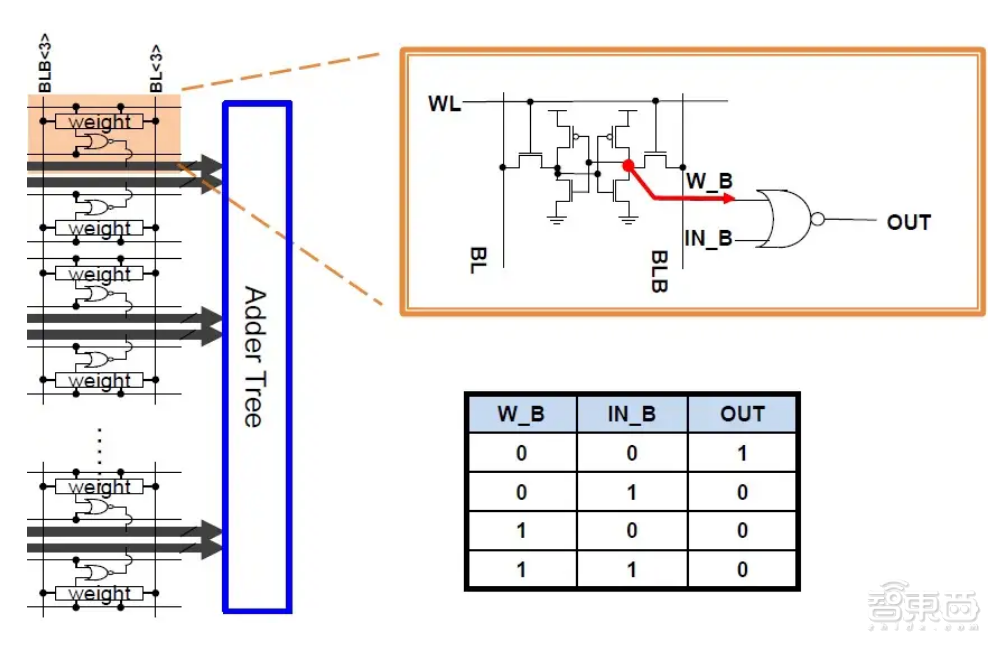
“X”是一个双输入或非门(NOR Gate),由一个数据输入和一个权重值作为输入,在面积效率和功率方面都具有一定优势。每个slice之间,集成了加法器树和部分累加逻辑。
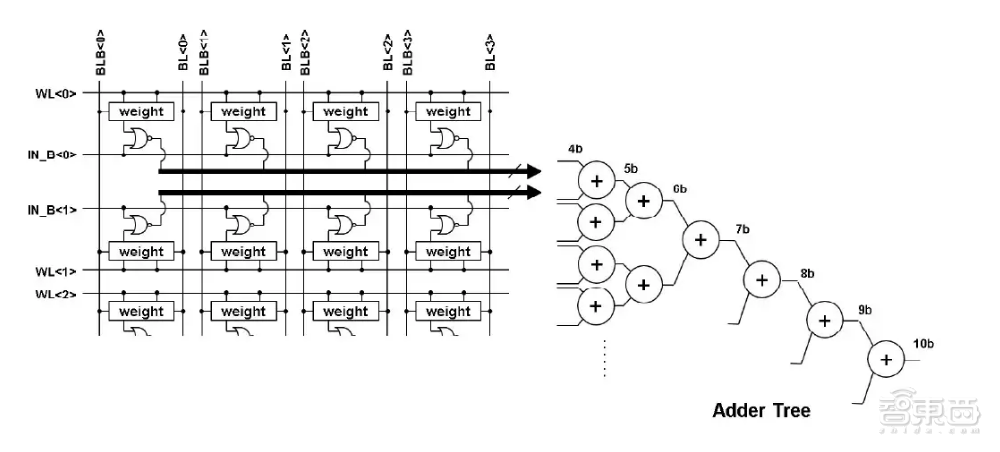
加法器树中的权重存储使用了传统的SRAM拓扑结构,其中的权重字线和位线做正常连接。对于一个6T-bit单元,每个单元的存储值就是或非门的一个输入。
每个slice的输出表示每个权重向量的部分乘积总和。扩展数组之外的其他逻辑电路提供了移位相加计算,以支持更宽的权重表示。例如,一个(有符号或无符号整数)16-bit权重将组合来自4个slice的累加结果。
台积电基于SRAM的全数字测试器件突出显示了256输入,16个slice(4-bit权重半字节)的宏设计。

▲台积电基于SRAM的全数字测试器件的显微图(来源:IEEE Xplore)
其基于SRAM的存内计算宏可以在阵列中提升更新权重的效率,而且该阵列基于数字逻辑的MAC操作可在很宽的电源电压范围内使用。
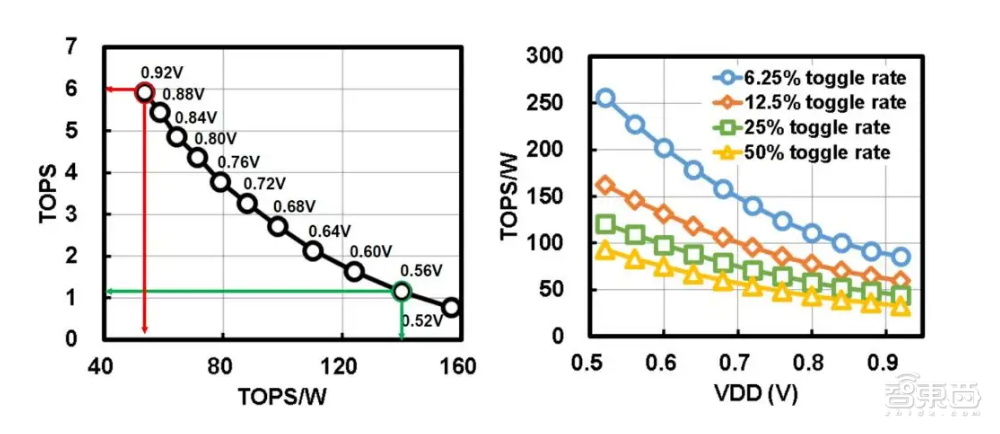
▲SRAM阵列的电源电压(TOPS)和功率效率(TOPS/W)测试性能(来源:IEEE Xplore)
尽管此存内计算是在较旧的22nm工艺中来测试,但是台积电的研究人员也提供了5nm节点的面积功率与功率效率估值。
与22nm节点相比,5nm节点的电源电压(TOPS)和功率效率(TOPS/W)将分别提升2.8倍和19倍。
从云到边缘设备,人工智能(AI)和机器学习(ML)被大范围的使用在图像分类、语音识别等任务。近年来,由于AI在边缘的优势,比如隐私、低延迟及对网络带宽的有效利用等,AI边缘设备的研究受到了慢慢的变多的关注。
但是,传统的计算架构,如CPU、GPU、FPGA等因为能耗问题很难满足AI边缘应用的未来需求。本次台积电的这种SRAM阵列通过在内存中进行计算,能够大大减少内存访问的能量消耗,或许能够解决AI边缘的能耗问题。
手机:188 2685 9701(微信同号)
安博体育能玩吗/安博电竞app安卓版-安博ios官网下载
地址东莞市寮步镇向西村村口街3号厂房